Skip to main content
Human Sensing Laboratory
Main menu
Home
Projects
The Lab
People
Publications
Software
Data
Contact
Live the experience
You are here
Home
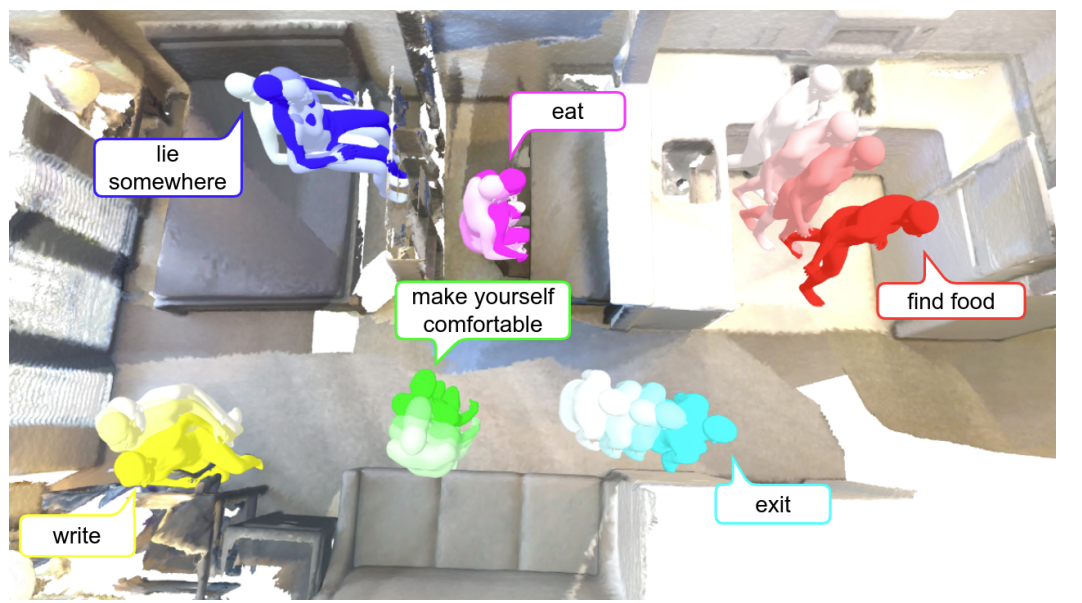
GHOST: Grounded Human Motion Generation with Open Vocabulary Scene-and-Text Contexts
Author:
Z. Milacski, K. Niinuma, R. Kawamura, F. de la Torre, L. Jeni
Image publication:
Published by:
IEEE/CVF Winter Conference on Applications of Computer Vision, 2025
file publication:
Milacski_GHOST_Grounded_Human_Motion_Generation_with_Open_Vocabulary_Scene-and-Text_Contexts_WACV_2025_paper.pdf
Link:
http://humansensing.cs.cmu.edu/node/601#overlay-context=node/616